


TL;DR
AI code reviewers are ruthlessly consistent, unemotional, and data‑driven. If we treat them as mirrors instead of threats, we can adopt their discipline — clear criteria, structured comments, zero ego — and add what they lack: context, judgment, and empathy. The payoff is faster reviews, fewer blind spots, and a healthier engineering culture. In this article I will try to explore how we can adopt one round of AI driven code review followed by human review and how we can become better human (or better team members) in the process.
Why This Article (and How It Connects to My Earlier One)
When we rolled out AI-driven code reviews, the initial goal was obvious: catch more defects, shrink review cycles. That happened. The surprise was subtler: the bot surfaced our shortcomings — bias, fatigue, politeness theatre, vague feedback, and gatekeeping.
A while back, in “Effective Code Review: The Human Aspect” (Medium), I argued that reviews are as much about people as they are about code — psychological safety, tone, clarity, and mentorship. This piece is the sequel: what can humans learn from machines to become better humans during review? We’re not handing judgment to silicon; we’re borrowing its discipline to polish our own.
The Objective
- Improve the codebase with less bias and more consistency. We want cleaner code without personalities or politics creeping in.
- Make human feedback kinder, clearer, and more actionable. Precision doesn’t have to be cold; kindness doesn’t have to be vague.
- Blend AI’s strengths with human judgment to build a sustainable review culture. Automation handles the repetitive; humans handle nuance.
This is not a “replace reviewers” manifesto. The agenda is clear. “learn from the mirror”.
The Human Factor: The Smells We Pretend Not to Notice
Let’s name the patterns we see but rarely document.
Halo/Horn Bias. Often the author’s reputation shapes the rigor of the review. Alice rarely breaks things, or John is expert of this field, so we skim. Bob once broke prod, Jane is known to write buggy code, so we nitpick. Code quality becomes a function of history and perception, not content.
Fatigue & Context Switching. Reviews squeezed between meetings or after hours lead to LGTM rubber stamps, or worse, missed concurrency bugs. Tired brains default to surface-level comments (“rename this var”) instead of deep reasoning (“does this retry logic leak resources?”). It often ends up with one LGTM comment after hundreds line of code and a nasty bug somewhere within the PR takes a breather.
Style Over Substance. We’ve all spent 15 minutes debating brace positions while a potential race condition slid through unchanged. It’s easier to argue about commas than distributed state. In my early days as Software Engineer, tab vs space used to be a huge debate in teams.
Vague, Unactionable Feedback. “This looks wrong.” Great, but what looks wrong and why? Vague comments push cognitive load back on the author and trigger defensiveness. I once had a lead, who used to comment in one or two characters. “?” was his favorite and if he is very surprised or worried (or whatever it is, he might know better, we never asked) then he ended up writing two of them together. “??” Even after 18 years down the line I find it funny when I think the real struggle we had to go through to decipher his comments in code.
Ego & Point-Scoring. Some comments are crafted to signal superiority (“Did you even test this?”, “What exactly were you thinking?”, “How could you … “) rather than to help. The author stops listening; the code doesn’t improve.
Inconsistency. Different reviewers, different standards. A junior can’t guess which invisible rulebook applies today. Frustration ensues; quality suffers. In a very recent case, we had to get our product certified in a lab for security. The same product was certified in another lab but as they were not in business we had to approach a different lab this time. The code that was certified by one lab was found vulnerable by another.
Owning these isn’t self-flagellation — it’s step one to fixing them. After all, you can’t fix something that you don’t believe exists.
What AI Reviewers Actually Do Well (and Why Devs Sometimes Prefer Them)
Modern AI review tools — Copilot PR reviews, CodeRabbit, Sonar + LLM explainers, GitHub code scanning with LLM summaries, bespoke internal bots — excel at a few repeatable things:
Consistency, Every Time. They don’t have off days. The same issue will be flagged on Monday morning and Friday night.
Pattern Recognition at Scale. They instantly spot duplicated code, common security footguns, NPE landmines, unbounded loops, and outdated cryptography. A 2,000-line diff is just another token stream to them.
Context Linking. Good bots reference past MRs/PRs: “This function resembles sanitizeInput() from MR #234—consider consolidating.” Humans could do this; machines just do it.
Structured Output. Many bots follow a predictable schema: Issue → Why it matters → Suggested fix → Reference. Authors know how to act on that.
Zero Ego, Zero Politics. There’s no tone to misread, no senior showing off. Ironically, some developers feel safer receiving blunt machine feedback than a peer’s snark.
Speed. It reviews in seconds. That alone reduces idle time and keeps flow uninterrupted.
That unemotional, templated nature is a feature, not a flaw, when your goal is clarity. Ask any junior dev who has to deal with a snobbish senior and he will take the cold, ruthless, brutally direct AI review comments any day than going through the experience with the senior developer.

What AI Still Can’t Do (and Probably Shouldn’t)
Let’s not romanticize. LLMs and rule engines are tools, not teammates.
Product & Domain Context. “This code runs at checkout; an extra DB hit here costs us money” is not in the training data unless you feed it. Prioritization comes from humans.
Trade-off Judgment. Ship now vs. refactor later, accept tech debt to unblock a critical release — those are organizational calls. These are better left to human being to decide.
Social & Team Conventions. Style guides can be encoded; evolving team norms and tacit agreements are negotiated by humans.
Mentorship & Emotional Intelligence. A bot can point out a mistake; it can’t sense a junior dev’s anxiety or tailor the tone to coach, not crush. Though sometimes it is the preferred medium, but in most of the cases a little human touch goes a long way.
Long-Horizon Architecture. Architecture is driven by roadmaps, org structure, and future bets. AI can propose patterns but can’t own the consequences.
Moral & Legal Responsibility. If an AI misses a security flaw that leaks PII, the liability doesn’t disappear. Humans are still on the hook.
AI is a scalpel — precise, sharp, and dangerous if wielded without a surgeon. Be the surgeon of the house and use the scalpel well. Also always keep in mind, it can (and often do) make mistakes. So take anything from AI with a pinch of salt.
Lessons Humans Should Steal From AI (and Humanize)
-
Detach Feedback From Identity
AI never says “you messed up.” It talks about code. Adopt that language: “This function…” instead of “You…”. You reduce defensiveness, increase receptivity.
Instead of: “You allowed empty strings again.”
Try: “The validation regex allows empty strings; should we enforce a minimum length?”Same problem, radically different psychological impact.
-
Make Comments Evidence-Based
Bots back claims with patterns or docs. We should too. “This is O(n²); with 10k items we’ll spike CPU. A map lookup drops it to O(n).” Link to perf dashboards, ADRs, CVEs, or style guides. Evidence beats opinion.
-
Use a Structured Comment Template
Borrow the bot schema:
i. Issue: What’s wrong? (Be concrete.)
ii. Impact/Risk: Why should anyone care?
iii. Suggestion: Offer a viable fix, not just a complaint.
iv. Reference: Doc/link/example if it strengthens the case.This reduces back-and-forth, especially across time zones.
-
Lead With Severity
Bots label findings (Critical/High/Medium/Low). Humans should triage too. Put the SQL injection before the variable naming. Ordering your comments signals priorities and respects the author’s time.
-
Be Specific, Actionable, and Brief
LLMs are verbose only if prompted that way. Their best comments are crisp. Train yourself to cut fluff. If a comment needs five paragraphs, maybe it’s a call or a design doc.
-
Automate the Repetitive; Guard Your Brain for the Hard Stuff
Let CI pipelines and bots handle formatting, lint rules, test coverage thresholds. Spend review calories on architecture, domain logic, and user impact. Humans shouldn’t argue with Linter.
-
Turn Reviews Into Mini-Learning Moments
Good AI suggestions show how to fix, not just what to fix. Do the same. “FYI: Using sealed types here makes illegal states unrepresentable” teaches and prevents recurrence.
-
Track Your Own Patterns
If a bot can bucket its findings, so can you. Keep a lightweight log: what issues do you flag repeatedly? Convert recurring comments into checklists, pre-commit hooks, or linters. Reduce repetition; scale yourself.
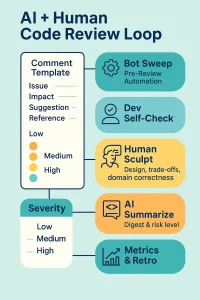
The Hybrid Flow: Let the Bot Sweep, Humans Sculpt
A practical pipeline you can adopt:
-
Pre-Review Automation.
i. Run static analysis, formatters, lint, and security scanners automatically.
ii. Kick an AI pre-review bot to post its first-pass findings on the PR/MR. -
Developer Self-Check.
i. Authors run the same AI (or at least a checklist) locally before opening a PR. Half the comments vanish before anyone sees them.
-
Human Review (Tiered & Focused).
i. Humans concentrate on design, trade-offs, domain correctness, and user impact
ii. Use the structured template; triage by severity.
iii. Pair or call when discussion exceeds a few comments. -
AI Summarizer (Optional but Handy).
Post-merge or post-review, a bot summarizes: “3 issues fixed, 1 deferred, risk: medium.” Useful for tracking and retros.
-
Retrospective Metrics.
Track PR cycle time, defect leakage, comment categories, rework rate, reviewer load. Adjust checklists and bot prompts quarterly.
AI Comment vs Human-Improved Version
Bot:
Possible NPE: user?.address!!.city may throw because address is nullable. Consider safe access or early return.
Human (After Learning From the Bot):
user?.address!!.city can still crash if address is null. Suggest user?.address?.city ?: return handleMissingCity() to avoid an NPE. This path triggers when profile completion is partial (see bug #482).
Severity: High (production crash)
Reference: Kotlin Null-Safety Guide
Same detection, richer context, clearer fix, prioritized severity. That’s the blend.
Cultural Norms to Nail Down
Tools won’t fix culture; norms will.
- Critique the code, celebrate the coder. Separate identity from output.
- Default to Helpfulness. If you can fix a trivial nit, do it. Don’t write a smug one-liner.
- No Drive-By Reviews. If you comment, follow through. Ghosting stalls merges and morale.
- Timebox & Rotate. Avoid reviewer burnout. Rotate domains; mentor up-and-coming reviewers.
- Feedback on Feedback. Meta-review your review comments quarterly. Are they clear? Respectful? Useful?
These echo themes from my earlier article: psychological safety and respect aren’t “soft”; they are foundational.
Opinion Corner
Treat the AI as your tireless junior reviewer — fast, blunt, and annoyingly thorough. Senior engineers then do two jobs: mentor humans and iteratively tune the bot (better prompts, better rules). Over time, your collective wisdom becomes codified both in people and pipelines. That’s how you scale quality without scaling pain.
Conclusion
AI didn’t just make our code cleaner; it held up a mirror to our review culture. By copying its discipline and infusing it with empathy and context, we get the best of both worlds: objective code reviews and a humane engineering environment. The machine showed us what objectivity looks like. It’s on us to add heart and judgment. AI showed us how to be objective; it’s up to us to stay human.
This article has also been published on our Medium page
